上周听了一场 Mnova Database 的线上培训,主讲是腾龙微波的杜老师(中科院上海药物所药物分析硕士出身,专攻生物核磁共振)。两个小时看下来,最大的感受不是"软件又多了几个按钮",而是终于有人把化学实验室那个老大难——数据存哪儿、怎么找回来、谁能看、算不算合规——用一套能落地的办法讲清楚了。
先说个熟悉的画面:课题组几年攒下的核磁 fid文件,"20230912-1""final-final-2",命名随心,师兄毕业带走记忆,换台电脑想找回某个中间体的氢谱碳谱基本靠翻文件夹碰运气。药企也好不到哪儿去——多台 NMR/LC‑MS 各连一台工控机,数据散落,中央服务器只留 PDF 报告,原始谱图想二次处理或审计?找不到,或找到了也不知道当初用的什么参数。
Mestrelab 的思路很直接:别把谱图当文件管,把它当"对象"管。 这就是 Mnova Database(Mnova DB)。
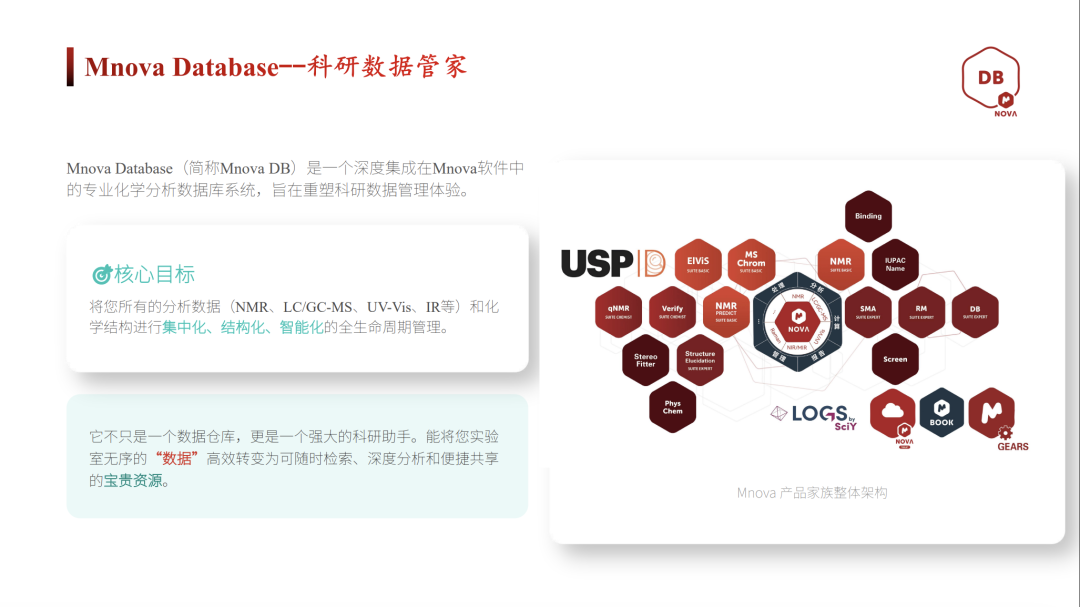
"它不是网盘,是带"记忆"的化学数据库"
杜老师在演示时打开 Mnova 17.0,右上角 Database 面板点 Connect,绿勾亮起说明连上了本地 MyData 库——这是个人版,数据就在本机,适合独立 PI 或博士生管自己的项目。
杜老师演示时先 Preview 了一个已有库——30 条记录,含结构、一维氢谱碳谱、二维谱甚至质谱;切换另一个库有 5 条 LC‑MS 记录。双击任一条可 Paste to Mnova 重新打开原处理状态——这一点很重要:它不是导出静态图片,而是把当时处理完的状态完整召回,你可以接着调相位、改基线,真正做到了数据全生命周期闭环。
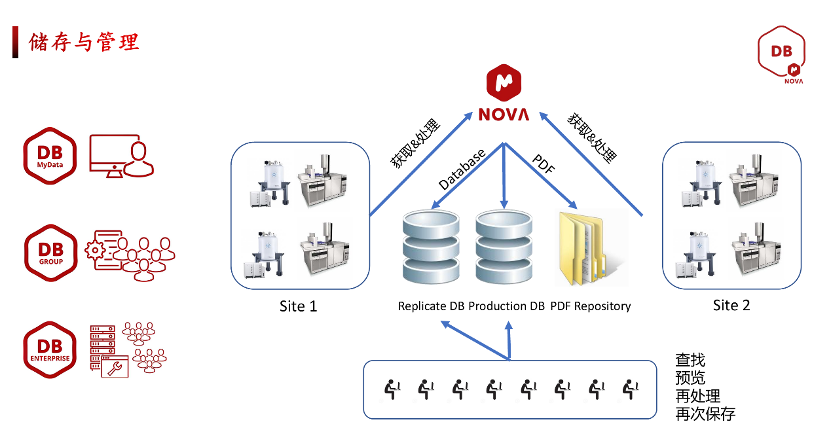
"画个布洛芬,库里所有相关谱图全出来"——现场演示检索
最让现场人眼前一亮的,是 DB Search 的检索逻辑。
杜老师打开一个含布洛芬(ibuprofen)的库,画好布洛芬结构,选 Substructure Search → Query,几乎瞬时返回命中,匹配度 1000 分,并直接关联出库中对应的 ¹H、¹³C 谱图。这就是子结构检索——你甚至可以只画一个母核片段,把所有含该片段的化合物及其谱图一次性捞出来,对做天然产物去重复、或者想确认"以前是不是合成过类似物"的人来说,这基本等于把几天翻文件夹的工作量压缩到几秒钟。
另一种情况是——你手上只有一张未知物的谱图,没有结构。这时可以用谱图检索(Peak Search),有三种匹配模式:
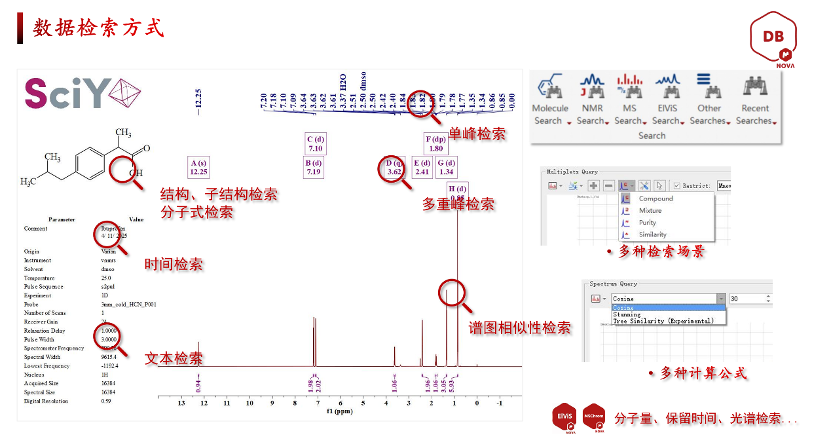
杜老师故意用一张不相关的谱图去搜,系统干净利落地返回 "No Match",没凑出任何似是而非的假阳性。她还提醒,算法可以按需求切换——做杂质筛查倾向用宽容匹配,做结构确证倾向用严格匹配,这点在实际使用中很关键。

当数据量大到手动检索不现实:Mgears 自动化
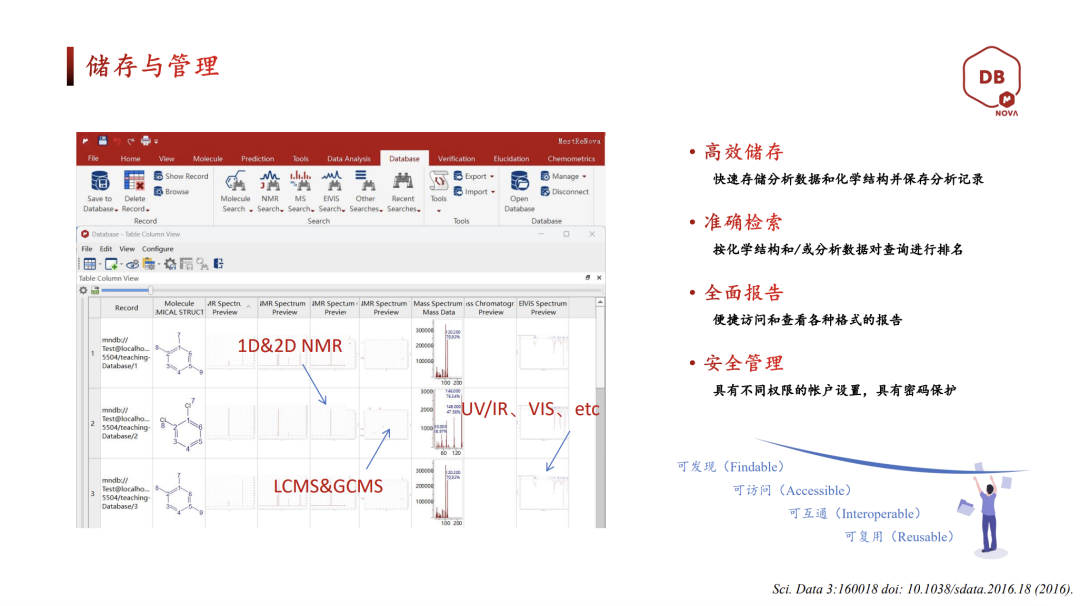
前面说的都是交互式操作,适合偶尔查一次。但杜老师抛出了一个真实案例——Genentech(基因泰克)每年处理约十万个样品,多台 NMR/LC-MS 分布在不同的城市,原先数据各存各的,每种化合物的NMR和LC-MS多份单独报告,中央服务器只留 PDF,复核原始数据几乎不可能,且人工处理导致方法不统一,数据一致性差,审计也难溯源。
他们的解法是 Mnova Gears + Mnova DB:
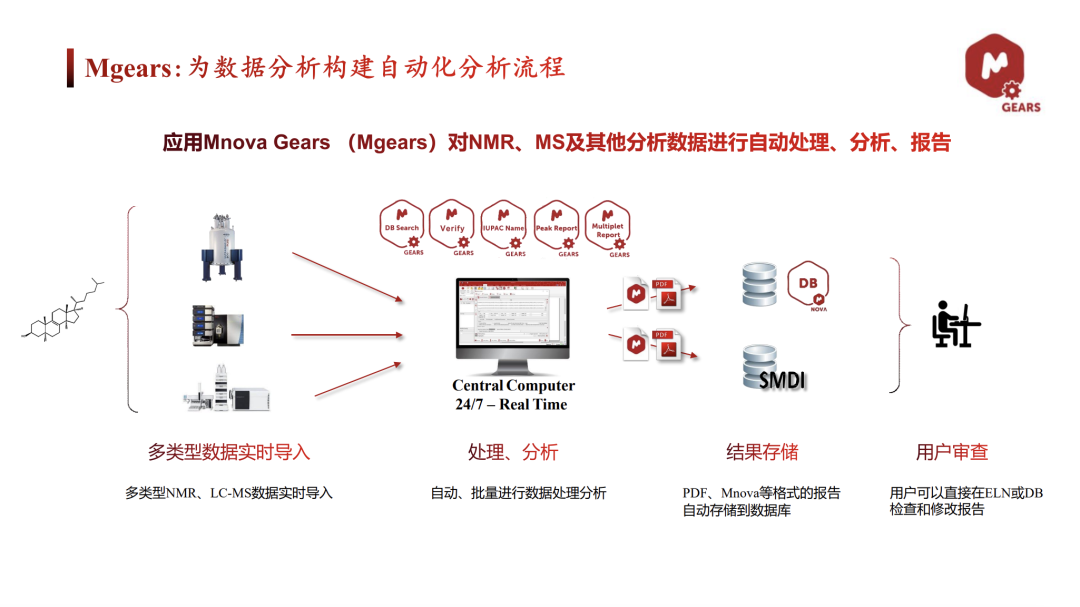
杜老师演示时用 5 个待测谱图文件夹 → Gears 指向含 30 个标准化合物(含布洛芬)的库 → 点 Run。后台进度条显示正在处理第 1/2/3 个……跑完直接出:
她还顺带提了一个公共安全领域的应用实例(SMASH 2023 poster):某机构建立 400+ 非法药物 NMR 标准库,海关查获样品上机后 Mgears 自动跑 DB Search,几分钟给出疑似匹配及打分排序,辅助快速筛查。

几个容易被忽略但很实用的点
高校课题组:
对于高校课题组,Mnova DB 最大的价值在于将“个人经验”沉淀为“课题组资产”,终结数据随人员毕业而流失的痛点。
以往,学生的核磁数据散落在个人电脑里,留下的往往是一堆难以复现的 fid文件和含义不明的文件夹名(如 final-final)。引入 Group DB(课题组版) 后,数据集中存储在局域网服务器上,建立起了课题组专属的标准谱图库。
药企/新材料研发/QC:
对于药企及新材料研发,Mnova DB + Gears 的核心价值在于构建符合 GxP 规范的数字化数据基础设施,解决数据完整性(Data Integrity)与效率的双重挑战。
针对多中心、多基地的布局,Enterprise DB 实现了数据的集中管控与权限隔离。无论是京沪两地的研发中心,还是全球多站点协作,都能在同一平台上实现 NMR、LC-MS 等数据的实时同步与统一标准,打破了数据孤岛,确保管理层能实时掌握项目全貌。
而在日常运营中,Mnova Gears 自动化工作流是提升 QC 效率的关键。它能将繁琐的人工处理(相位、基线校正)固化为标准模板,7x24 小时无人值守地批量抓取仪器数据、自动检索标准库(如 400+ 非法药物库)、并生成分析报告。最重要的是,全流程生成不可篡改的 Log 文件,详细记录谁在何时做了什么操作(时间戳,签名等),完美满足 FDA 21 CFR Part 11 等法规对审计追踪(Audit Trail)的严苛要求,让数据合规不再是负担。
💬 互动讨论

返回列表

微信公众号
